Classifier Calibration
Peter Flach 
University of Bristol
Miquel Perello Nieto
University of Bristol
Changing the numbers slightly
| \(\hat{p}\) | \(y\) | |
|---|---|---|
| 0 1 |
0.1 0.2 |
0 0 |
| 2 3 |
0.3 0.4 |
0 1 |
| 4 5 6 |
0.6 0.7 0.8 |
0 1 1 |
| 7 | 0.9 | 1 |
Or should we group the forecasts differently?
| \(\hat{p}\) | \(y\) | |
|---|---|---|
| 0 1 2 3 |
0.1 0.2 0.3 0.4 |
0 0 0 1 |
| 4 5 6 7 |
0.6 0.7 0.8 0.9 |
0 1 1 1 |
Or not at all?
| \(\hat{p}\) | \(y\) | |
|---|---|---|
| 0 | 0.1 | 0 |
| 1 | 0.2 | 0 |
| 2 | 0.3 | 0 |
| 3 | 0.4 | 1 |
| 4 | 0.6 | 0 |
| 5 | 0.7 | 1 |
| 6 | 0.8 | 1 |
| 7 | 0.9 | 1 |
Questions and answers
Q&A 1
Question 1
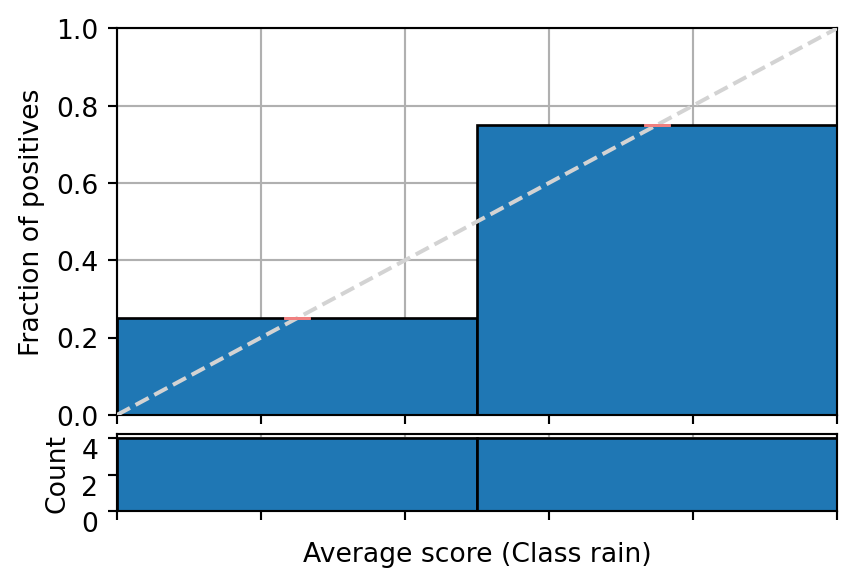
A binary classifier for weather predictions produces a score of 0.1 for rain two times but it does not rain, two times 0.4 and it rains only once, five times 0.6 and it rains 80% of the times and one time 0.9 and it rains. Does the following reliability diagram show that information?
Q&A 2
Question 2
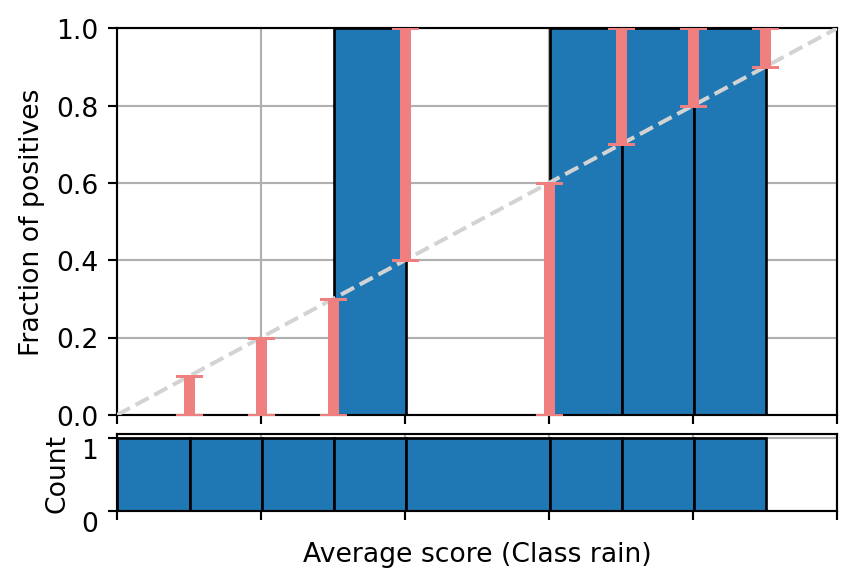
A binary classifier for weather predictions produces a score of 0.1 for rain two times and it rains once, three times 0.4 and it rains two times, four times 0.6 and it rains once and one time 0.9 and it rains. Does the following reliability diagram show that information?
Q&A 3
Question 3
Do we need multiple instances in each bin in order to visualise a reliability diagram?
Q&A 4
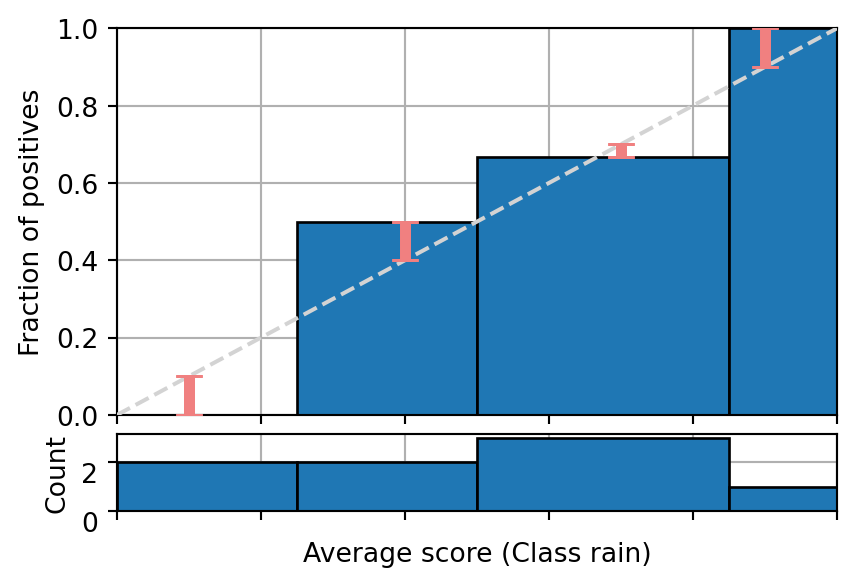
Question 4
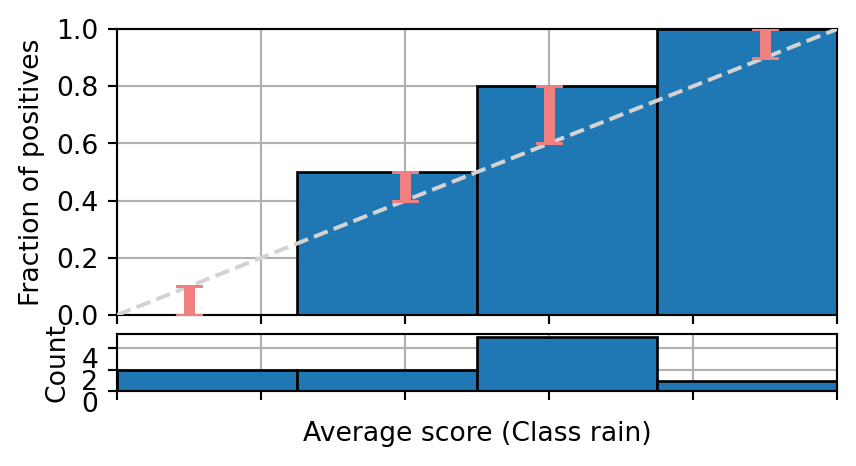
The following figure shows the reliability diagram of a binary classifier on enough samples to be statistically significant. Is the model calibrated, producing under-estimates or over-estimates?
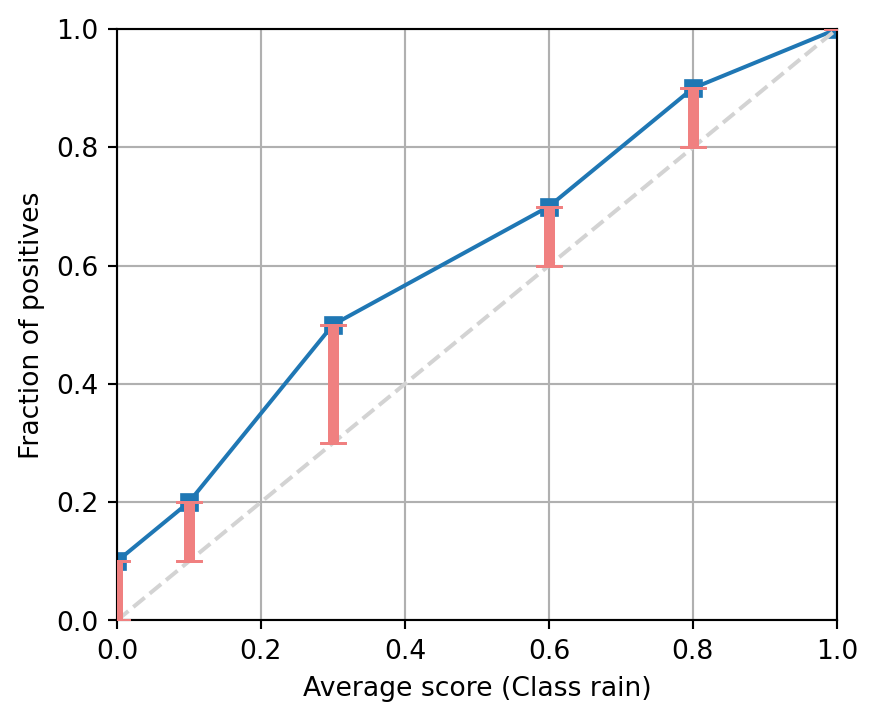
Q&A 5
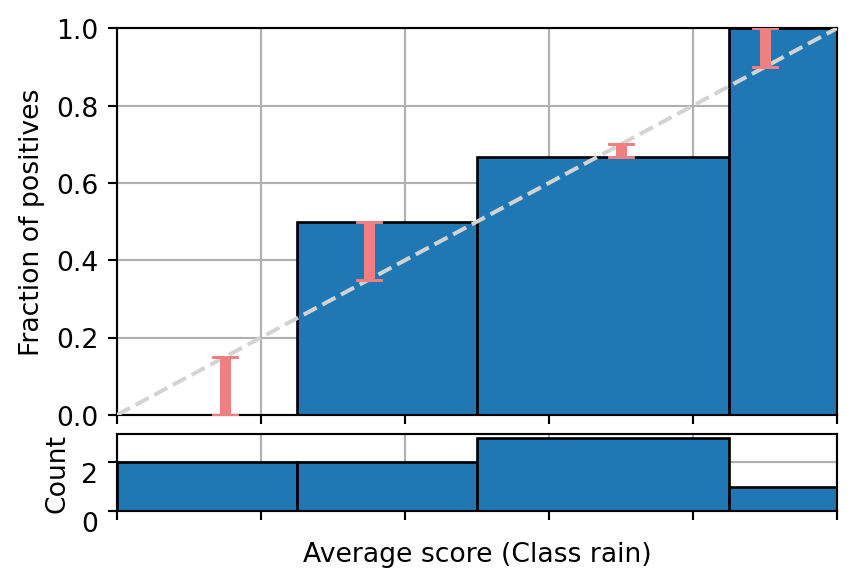
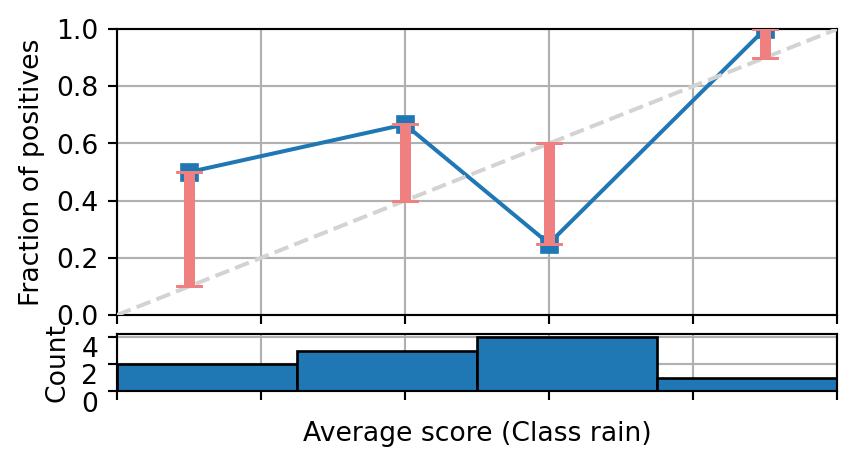
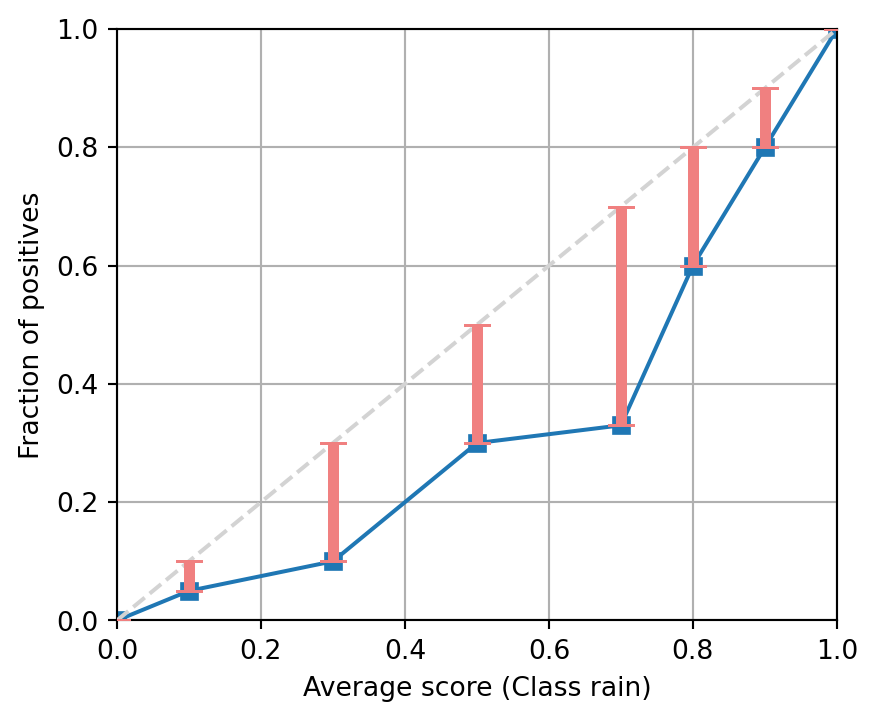
Question 5
The following figure shows the reliability diagram of a binary classifier on enough samples to be statistically significant. Is the model calibrated, producing under-estimates or over-estimates?
Underconfidence example
- Underconfidence typically gives sigmoidal distortions.
- To calibrate these means to pull predicted probabilities away from the centre.
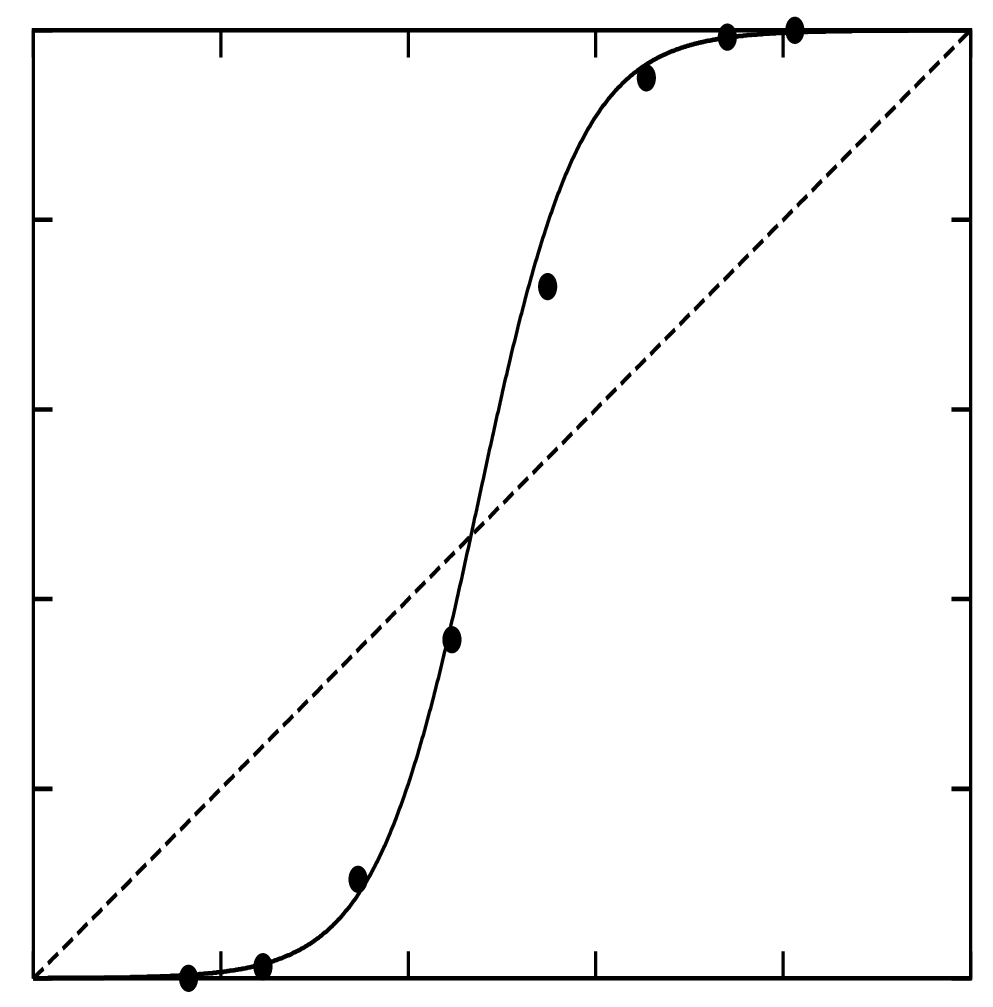
Source: (Niculescu-Mizil and Caruana 2005)
Overconfidence example
- Overconfidence is very common, and usually a consequence of over-counting evidence.
- Here, distortions are inverse-sigmoidal
- Calibrating these means to push predicted probabilities toward the centre.
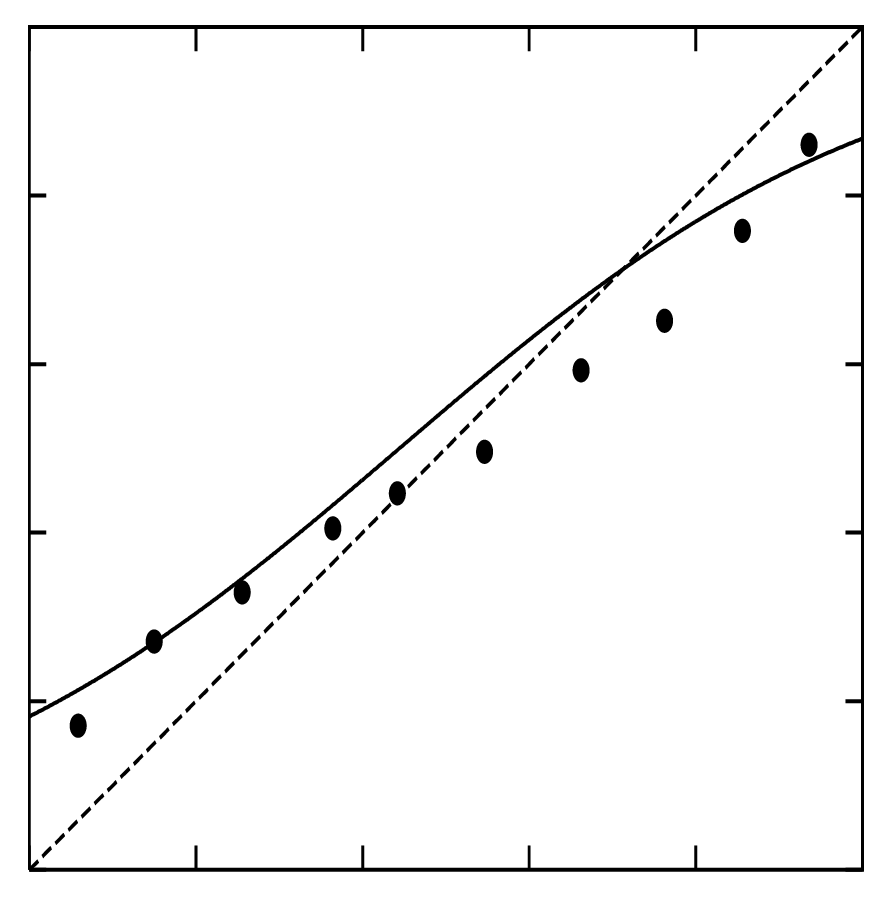
Source: (Niculescu-Mizil and Caruana 2005)
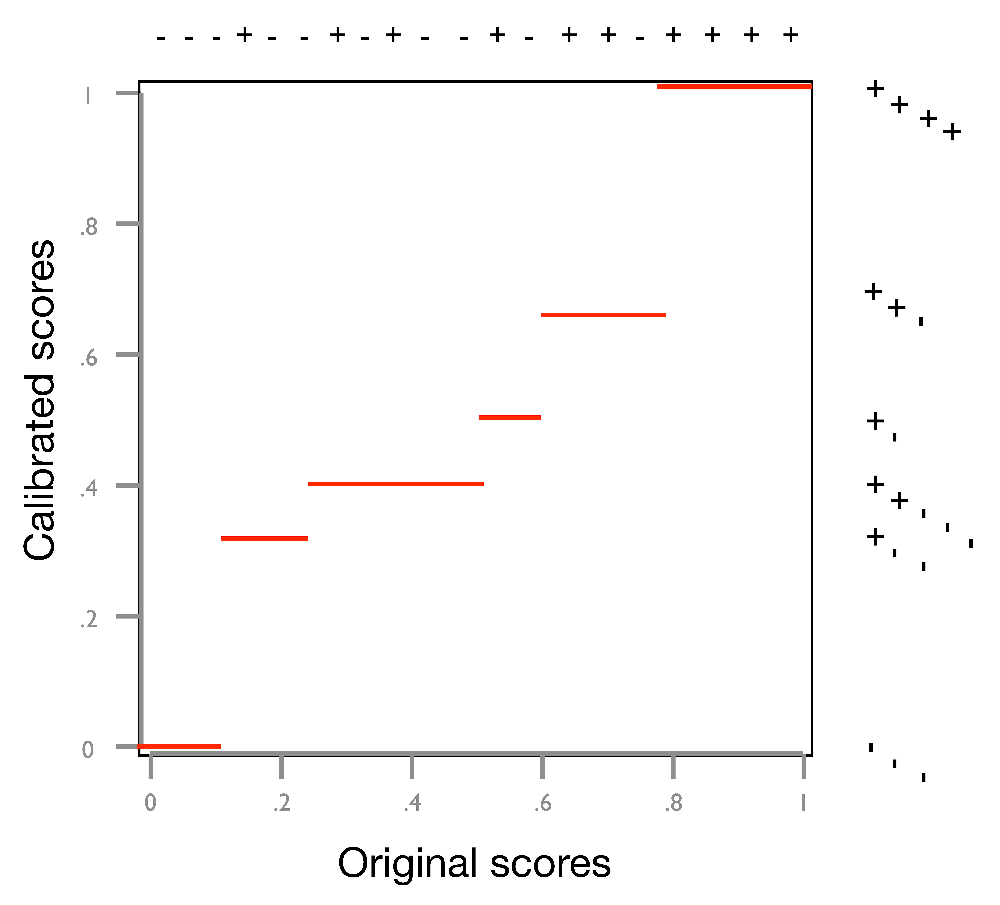
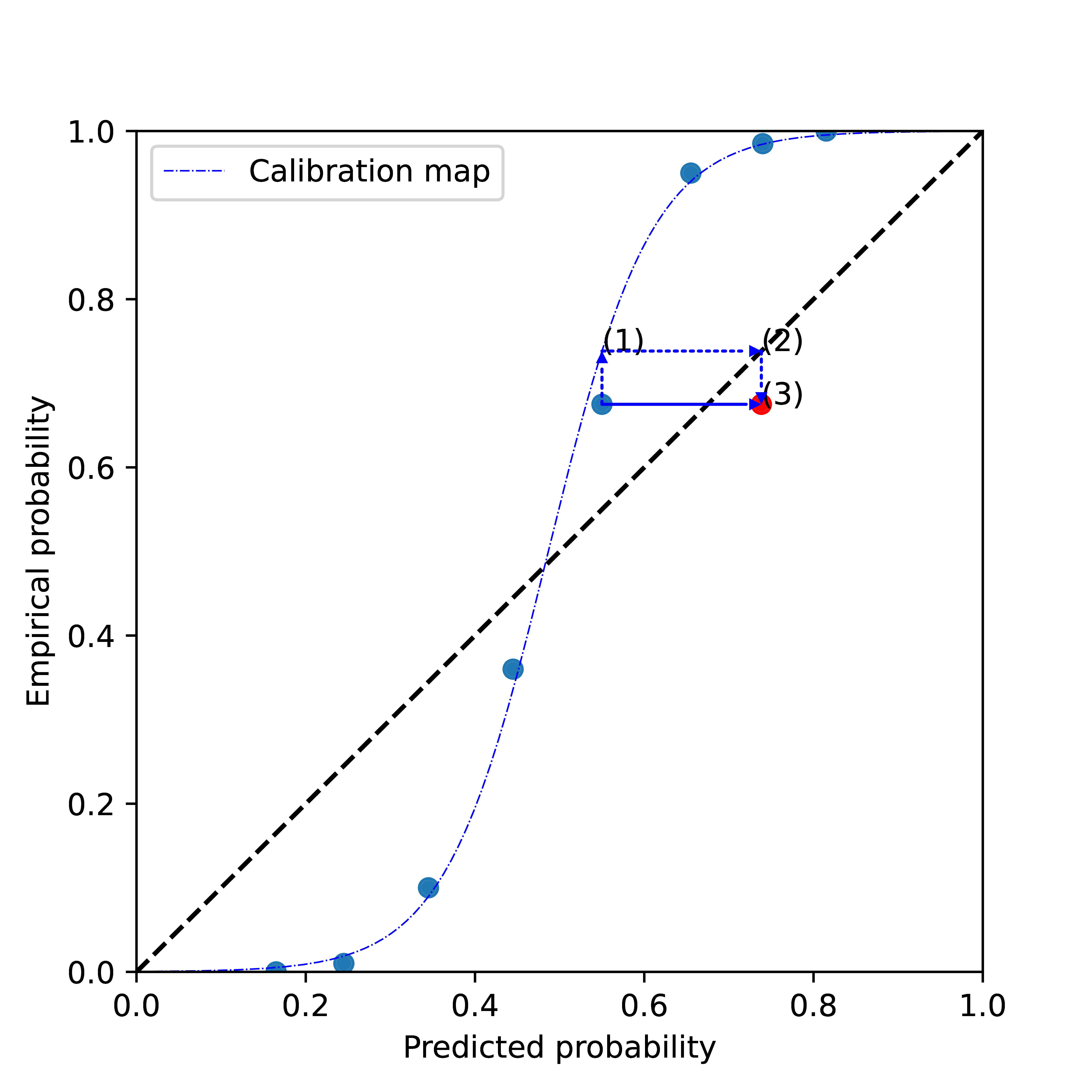
Why fitting the distortions helps with calibration
In clockwise direction, the dotted arrows show:
- using a point’s uncalibrated score on the \(x\)-axis as input to the calibration map,
- mapping the resulting output back to the diagonal, and
- combine with the empirical probability of the point we started from.
The closer the original point is to the fitted calibration map, the closer the calibrated point (in red) will be to the diagonal.
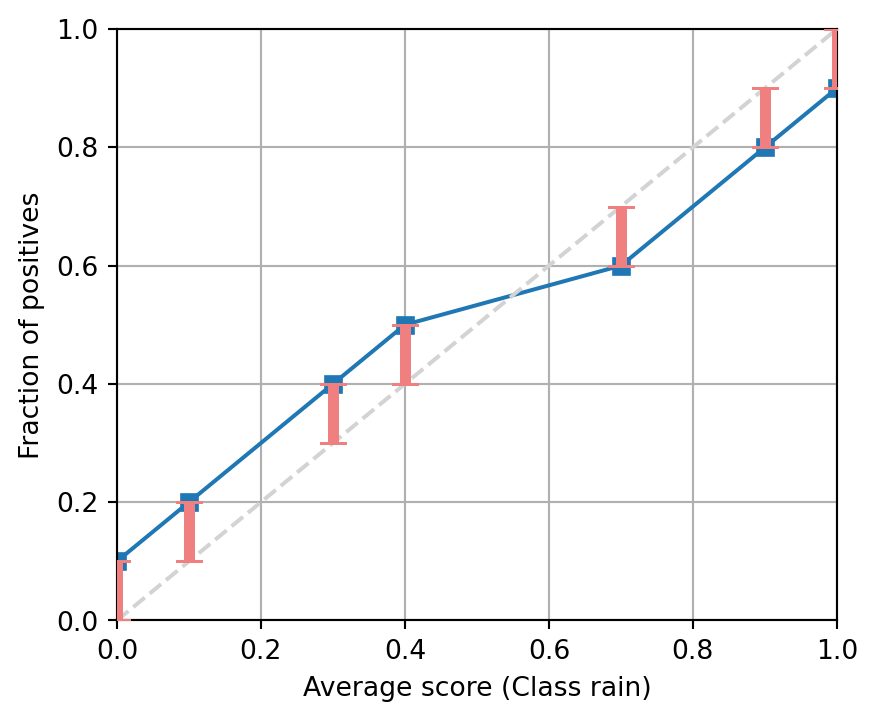
Questions and answers
Q&A 1
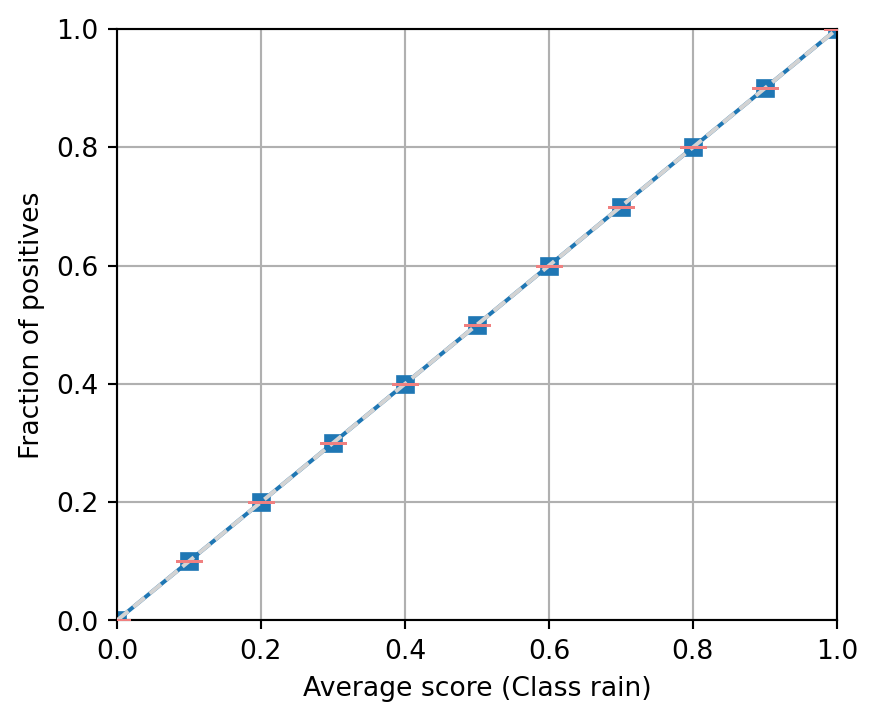
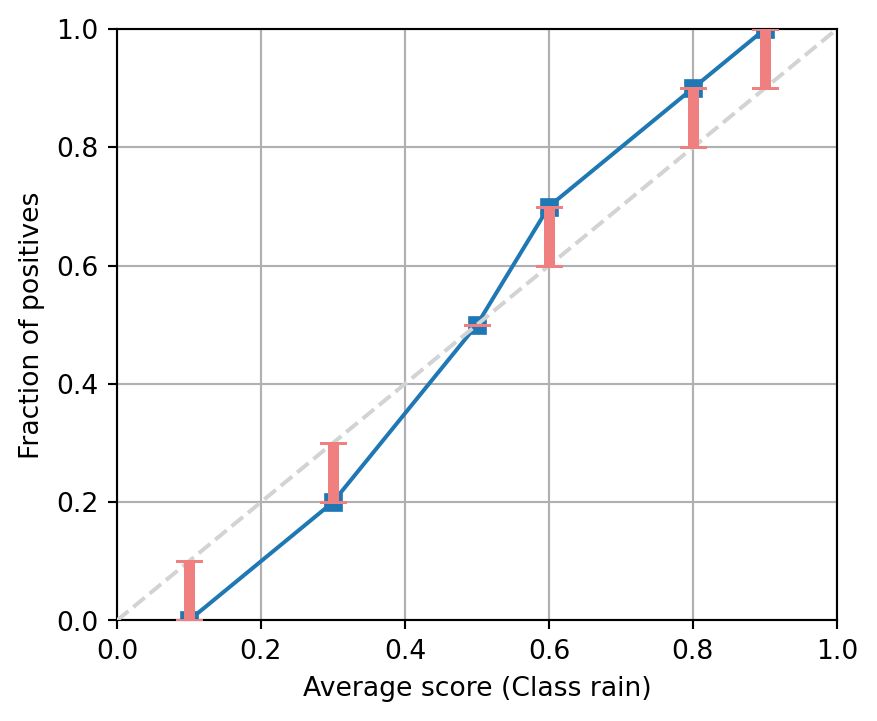
Question
The following figures show the reliability diagram of several binary classifiers. Assuming that there are enough samples on each bin, indicate if the model seems calibrated, over-confident or under-confident.
Q&A 2
Q&A 3
Q&A 4
Question
Can a binary classifier show a calibrated reliability diagram with a number of equally distributed bins, and a non-calibrated one with a higher number of equally distributed bins?
Platt scaling
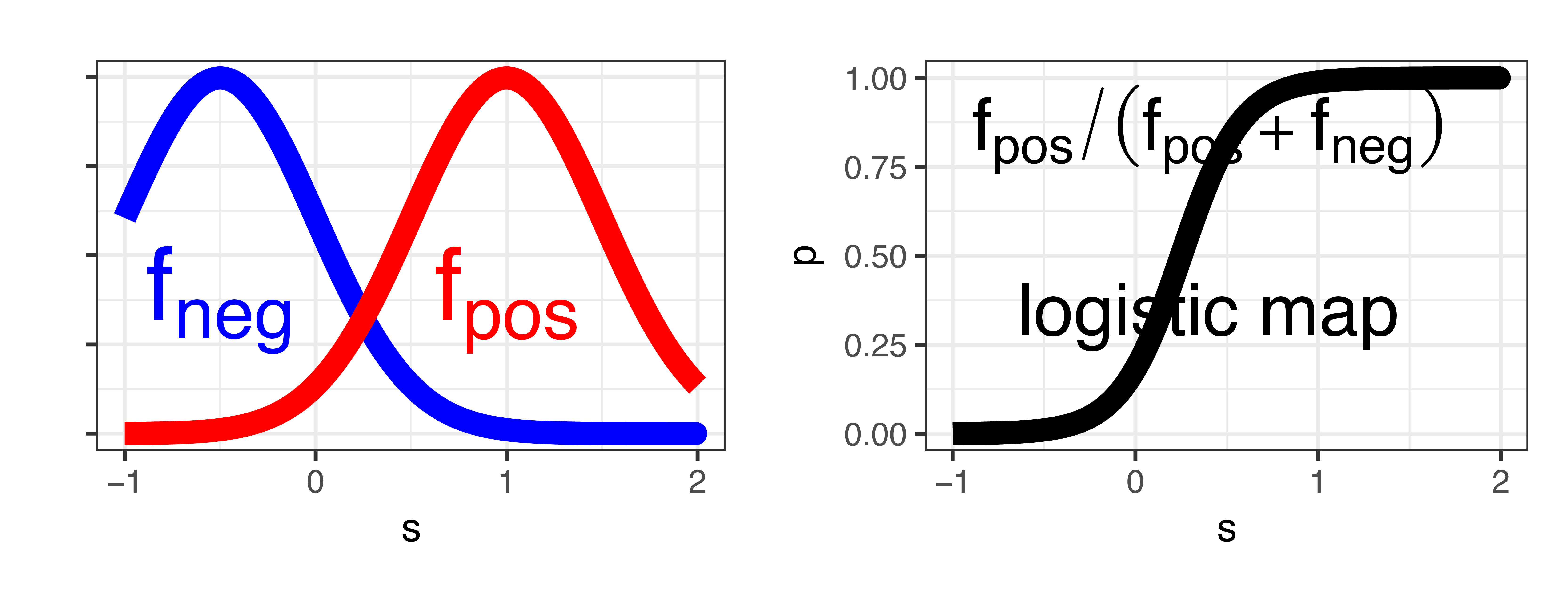
\[\begin{align*} p(s; w, m) &= \frac{1}{1+\exp(-w(s-m))}\\ w &= (\mu_{\textit{pos}}-\mu_{\textit{neg}})/\sigma^2, m = (\mu_{\textit{pos}}+\mu_{\textit{neg}})/2 \end{align*}\]
Beta calibration
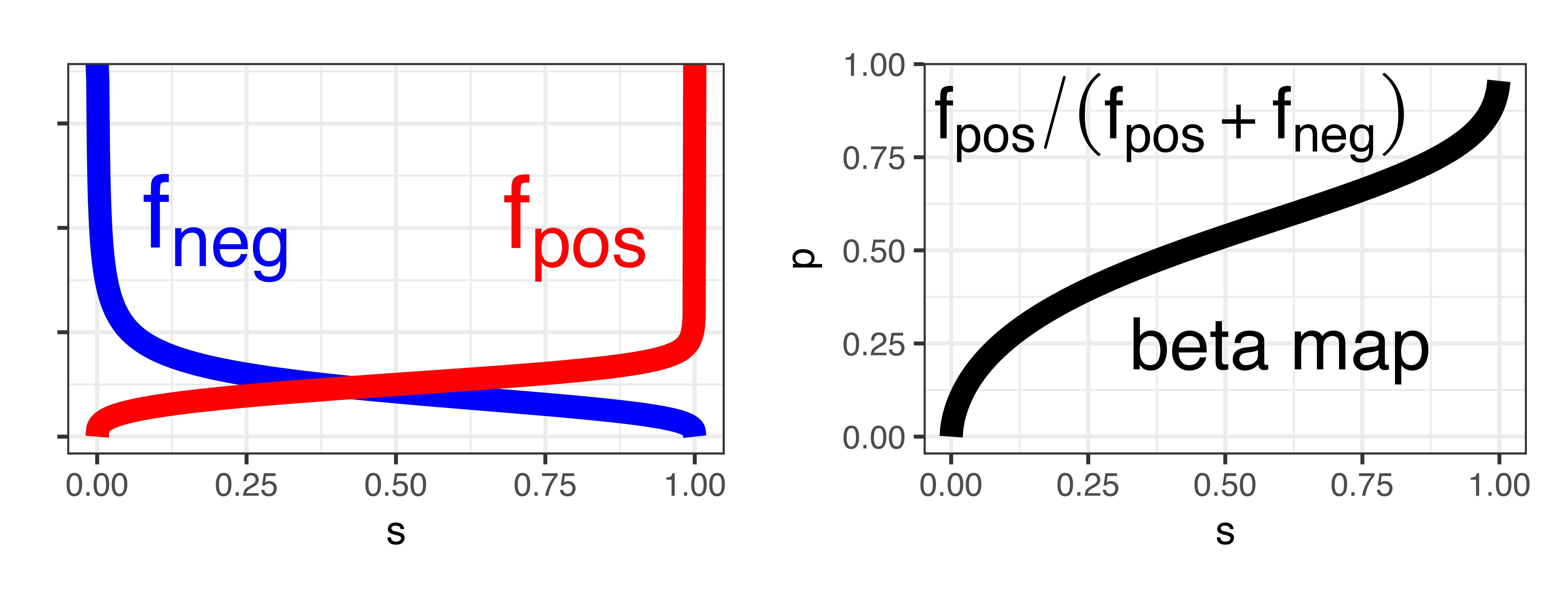
\[\begin{align*} p(s; a, b, c) &= \frac{1}{1+\exp(-a \ln s - b \ln (1-s) - c)} \\ a &= \alpha_{\textit{pos}}-\alpha_{\textit{neg}}, b = \beta_{\textit{neg}}-\beta_{\textit{pos}} \end{align*}\]
Isotonic regression