Introduction to Optimal Decision Making
Miquel Perello Nieto 
University of Bristol
Optimal Decision Making. Why and how?
- The objective is to classify a new instance into one of the possible classes in an optimal manner.
- This may be important in critical applications: e.g. medical diagnosis (Begoli, Bhattacharya, and Kusnezov 2019; Yang, Steinfeld, and Zimmerman 2019), self-driving cars (Qayyum et al. 2020; Mullins et al. 2018), extreme weather prediction, finances (Nti, Adekoya, and Weyori 2020).
![Example of critical applications]()
- It is necessary to know what are the consequences of making each prediction (costs or gains).
- One way to make optimal decisions is with cost-sensitive classification.
- Can we make optimal decisions with any type of classifier?
Optimal decisions with different types of model
- Class estimation: Outputs a class prediction.
- Class estimation with option of abstaining: Outputs a class prediction or abstains (Coenen, Abdullah, and Guns 2020; Mozannar and Sontag 2020)
- Rankings estimation: Outputs a ranked list of possible classes (Brinker and Hüllermeier 2020).
- Score surrogates: Outputs a continuous score which is commonly a surrogate for classification (e.g. Support Vector Machines).
- Probability estimation: Outputs class posterior probability estimates (e.g. Logistic Regression, naive Bayes, Artificial Neural Networks), or provides class counts which can be interpreted as proportions (e.g. decision trees, random forests, k-nearest neightbour) (Zadrozny and Elkan 2001).
- Other types of outputs: Some examples are possibility theory (Dubois and Prade 2001), credal sets (Levi 1980), conformal predictions (Vovk, Gammerman, and Shafer 2005), multi-label (Alotaibi and Flach 2021).


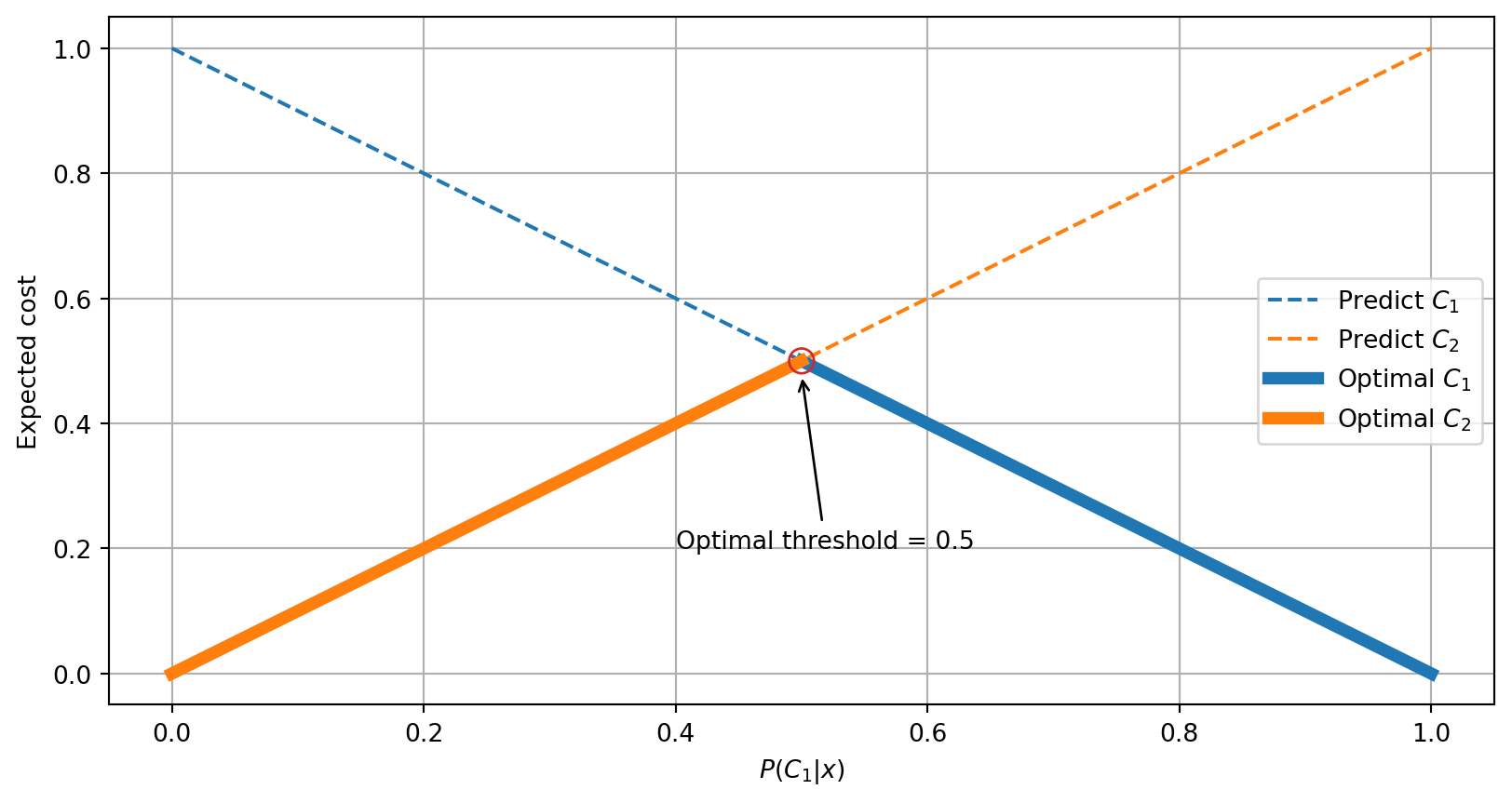
Class Domination
The following is an example of class domination in which predicting class \(C_1\) will always have a lower expected cost.
| Predicted \(C_1\) | Predicted \(C_2\) | |
|---|---|---|
| True \(C_1\) | \(\color{DarkGreen}{0}\) | \(\color{DarkRed}{1}\) |
| True \(C_2\) | \(\color{DarkRed}{0.4}\) | \(\color{DarkGreen}{0.5}\) |
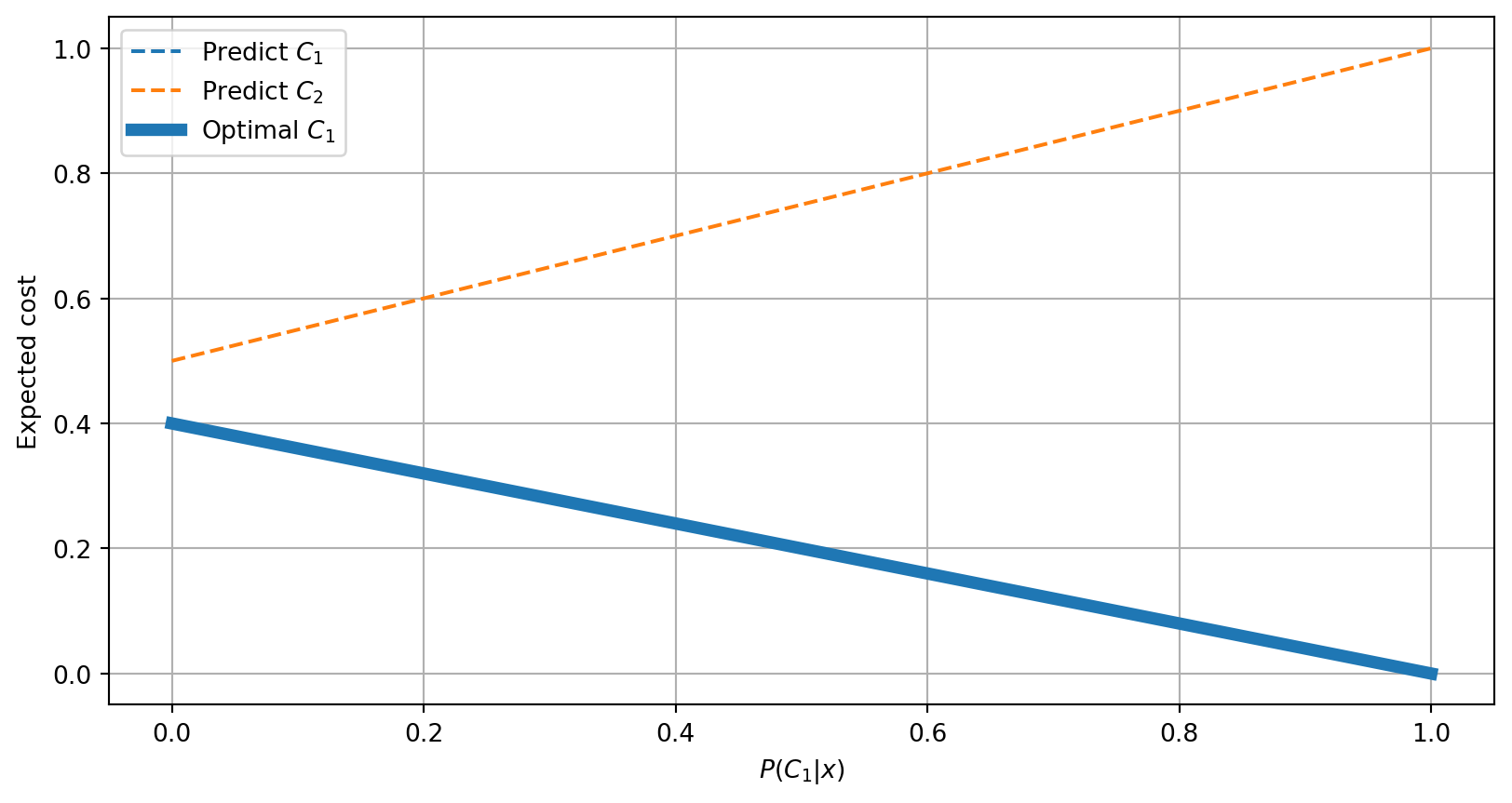
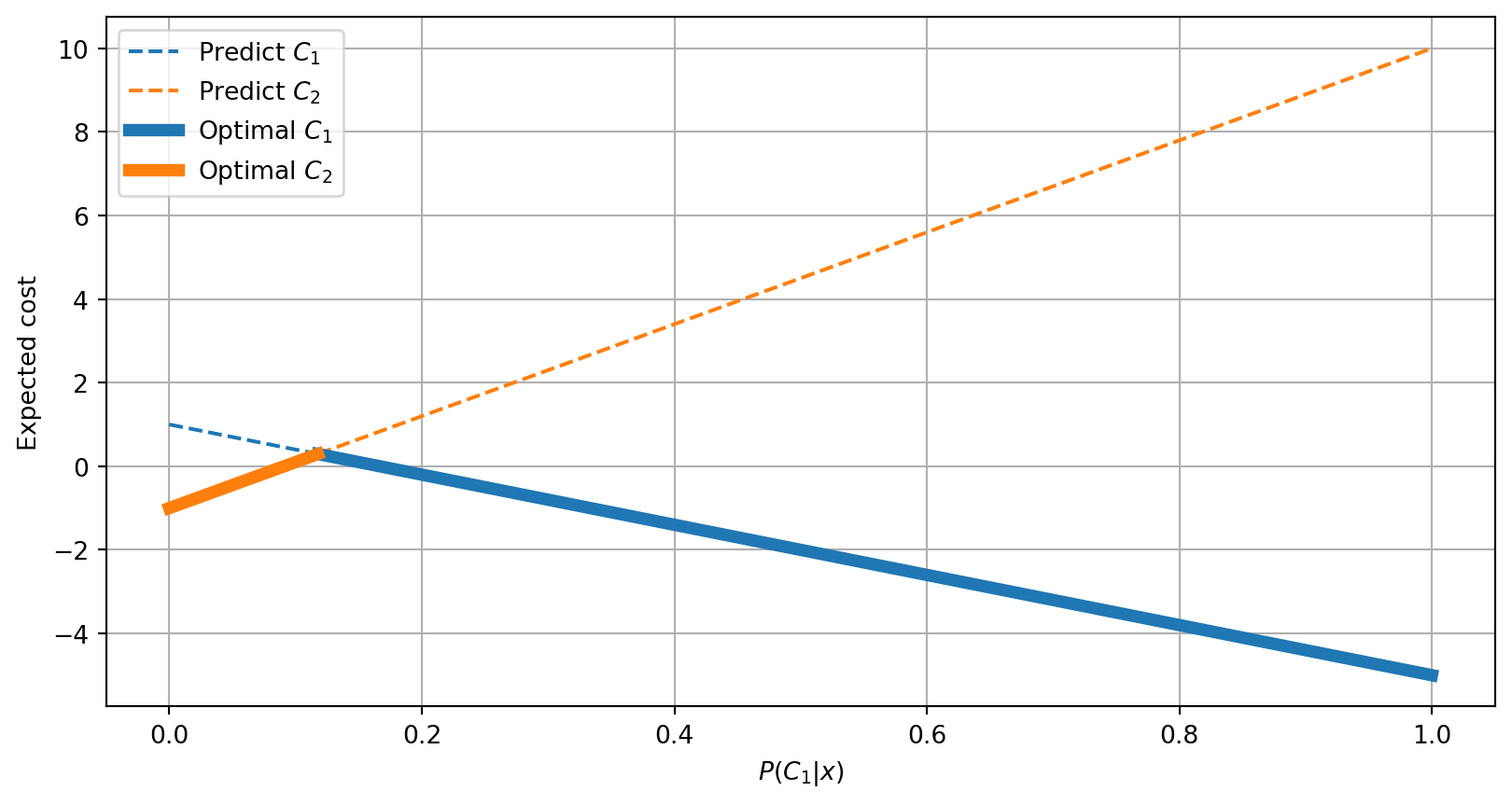
In this case, for a posterior probability vector \([0.4, 0.6]\) we would expect
- Predicting Class 1 will have an expected cost of \(-5 \times 0.4 + 1 \times 0.6 = \mathbf{\color{DarkGreen}{-1.4}}\)
- Predicting Class 2 will have an expected cost of \(10 \times 0.4 - 1 \times 0.6 = \color{DarkRed}{3.4}\)
Ternary expected cost isolines per decision
| Predicted \(C_1\) | Predicted \(C_2\) | Predicted \(C_3\) | |
|---|---|---|---|
| True \(C_1\) | \(\color{DarkGreen}{-10}\) | \(\color{DarkRed}{20}\) | \(\color{DarkRed}{30}\) |
| True \(C_2\) | \(\color{DarkRed}{40}\) | \(\color{DarkGreen}{-50}\) | \(\color{DarkRed}{60}\) |
| True \(C_3\) | \(\color{DarkRed}{70}\) | \(\color{DarkRed}{80}\) | |
| \(\color{DarkGreen}{-90}\) |
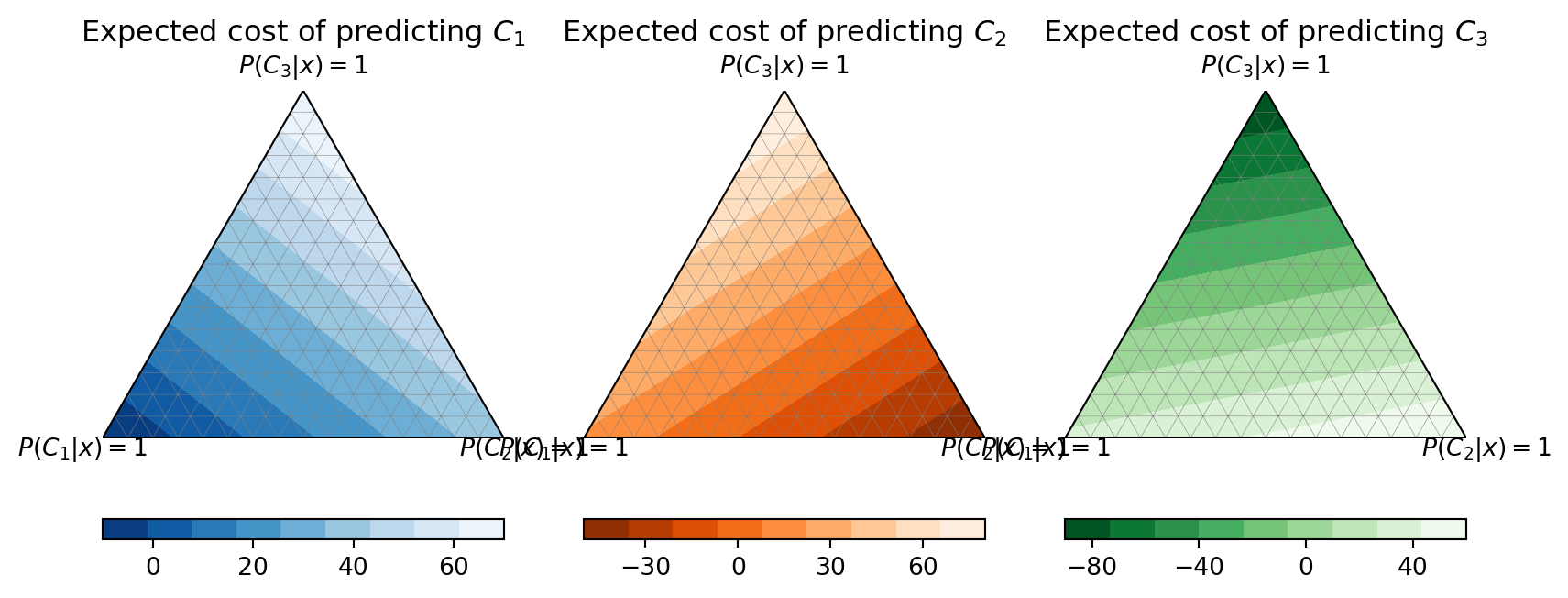
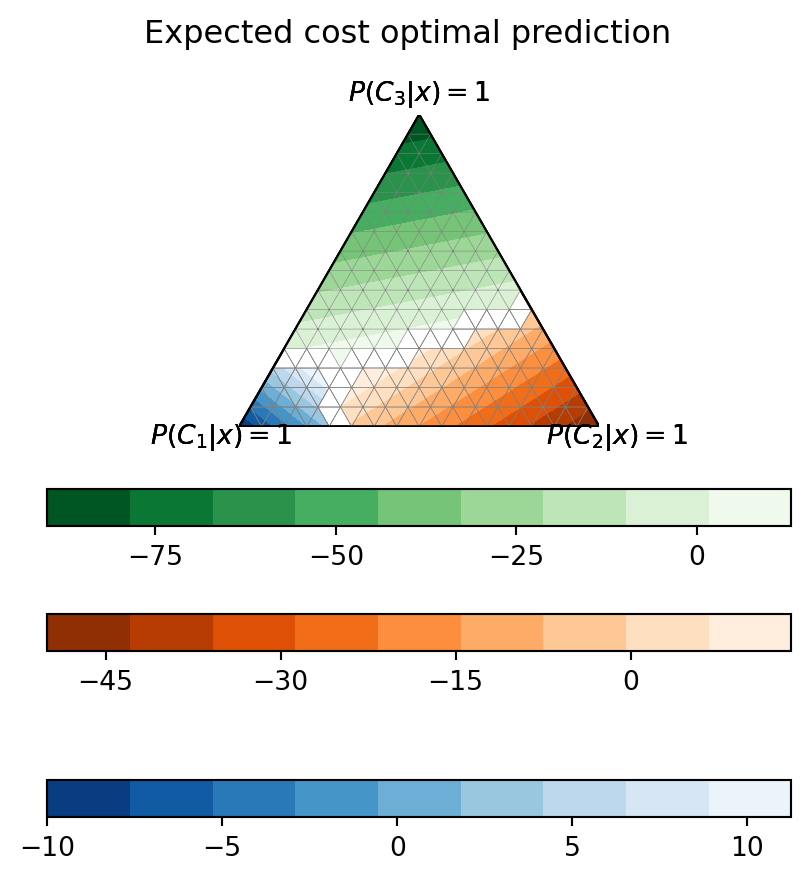
Ternary hyperplanes optimal decision combined
| Predicted \(C_1\) | Predicted \(C_2\) | Predicted \(C_3\) | |
|---|---|---|---|
| True \(C_1\) | \(\color{DarkGreen}{-10}\) | \(\color{DarkRed}{20}\) | \(\color{DarkRed}{30}\) |
| True \(C_2\) | \(\color{DarkRed}{40}\) | \(\color{DarkGreen}{-50}\) | \(\color{DarkRed}{60}\) |
| True \(C_3\) | \(\color{DarkRed}{70}\) | \(\color{DarkRed}{80}\) | |
| \(\color{DarkGreen}{-90}\) |
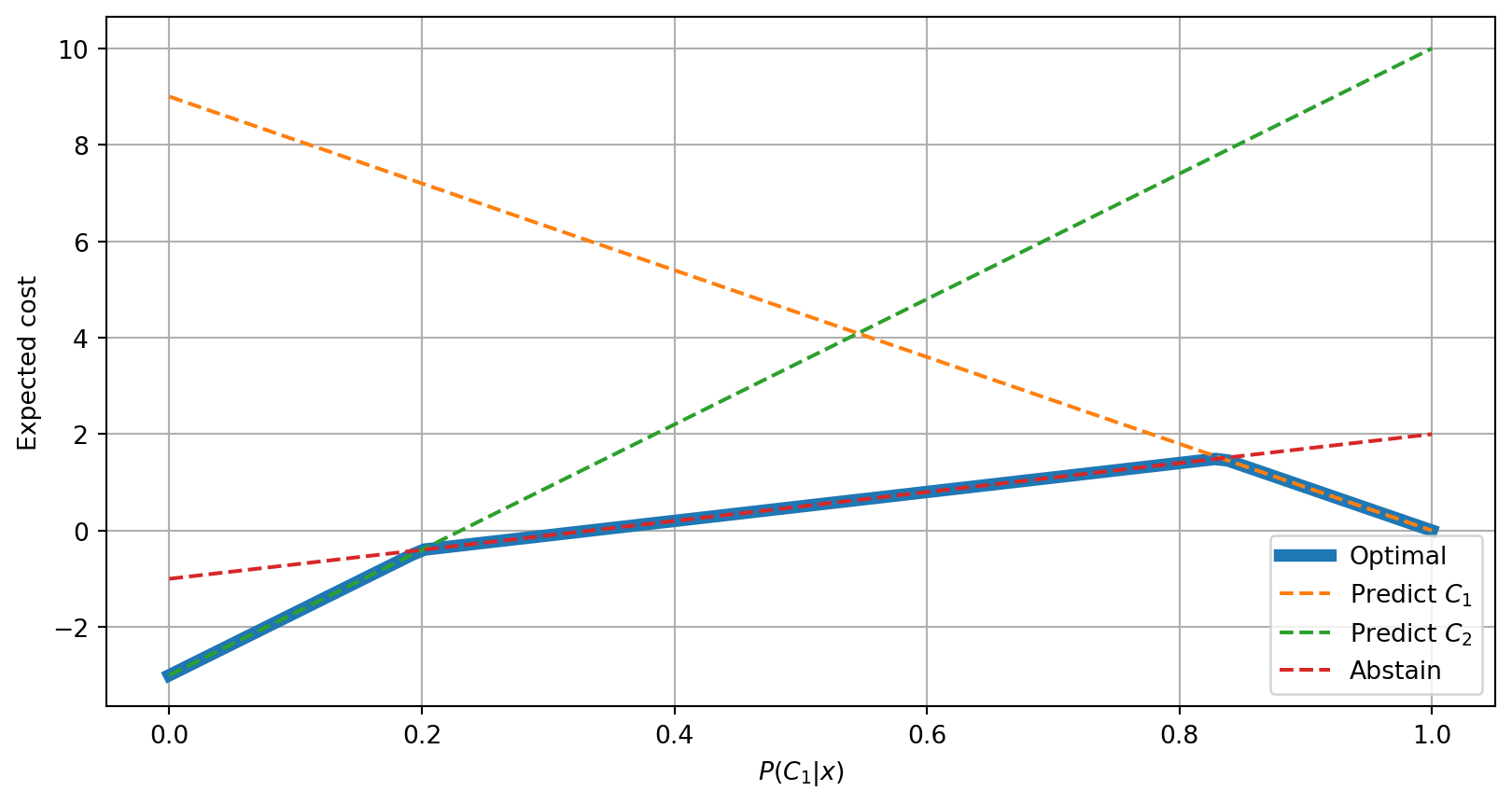
Option to abstain cost lines
| Predicted \(C_1\) | Predicted \(C_2\) | Abstain | |
|---|---|---|---|
| True \(C_1\) | \(\color{DarkGreen}{0}\) | \(\color{DarkRed}{10}\) | \(\color{DarkRed}{2}\) |
| True \(C_2\) | \(\color{DarkRed}{9}\) | \(\color{DarkGreen}{-3}\) | \(\color{DarkRed}{2}\) |
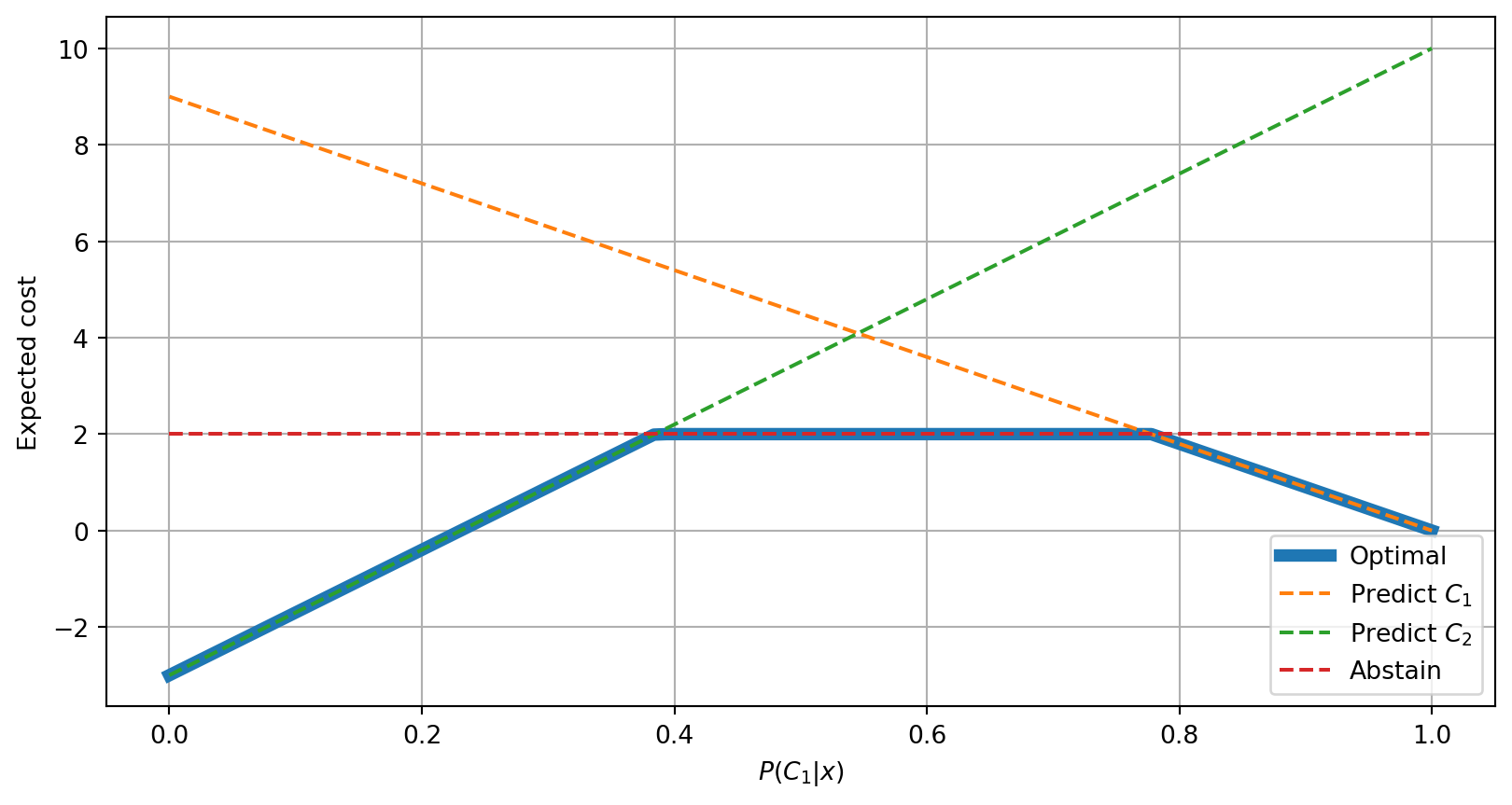
Option to abstain different costs
The following is another example in which abstaining from making a prediction if the true class was \(C_2\) would incur into a gain.
| Predicted \(C_1\) | Predicted \(C_2\) | Abstain | |
|---|---|---|---|
| True \(C_1\) | \(\color{DarkGreen}{0}\) | \(\color{DarkRed}{10}\) | \(\color{DarkRed}{2}\) |
| True \(C_2\) | \(\color{DarkRed}{9}\) | \(\color{DarkGreen}{-3}\) | \(\color{DarkGreen}{-1}\) |